
 My first encounter with Bloom Filter was in 2018. We were preparing for GDPR migration. So, our team manager suggested that we could use this data structure to anonymize personal data (PII) stored in our servers. To fully understand what’s a Bloom Filter, I decided to write it from scratch.
So what is a Bloom filter in first place?
My first encounter with Bloom Filter was in 2018. We were preparing for GDPR migration. So, our team manager suggested that we could use this data structure to anonymize personal data (PII) stored in our servers. To fully understand what’s a Bloom Filter, I decided to write it from scratch.
So what is a Bloom filter in first place?
A Bloom Filter is a probabilistic data structure that is used to check the existence of an element in a set. It is mainly used for space efficiency. The price paid for that is accuracy -> that’s why it’s called probabilistic data structure. In other words, there is the possibility for false positive values. The Bloom Filter claims that the element exists in the set but in realty it’s not.
To resume that, there are two cases when checking the existence of an element:
- Element is definitely not in the set.
- Element is Maybe in the set (possibility of False positives).
Note: If the element is not on the set, the Bloom Filter will never claim that it exists (impossible to have false negative).
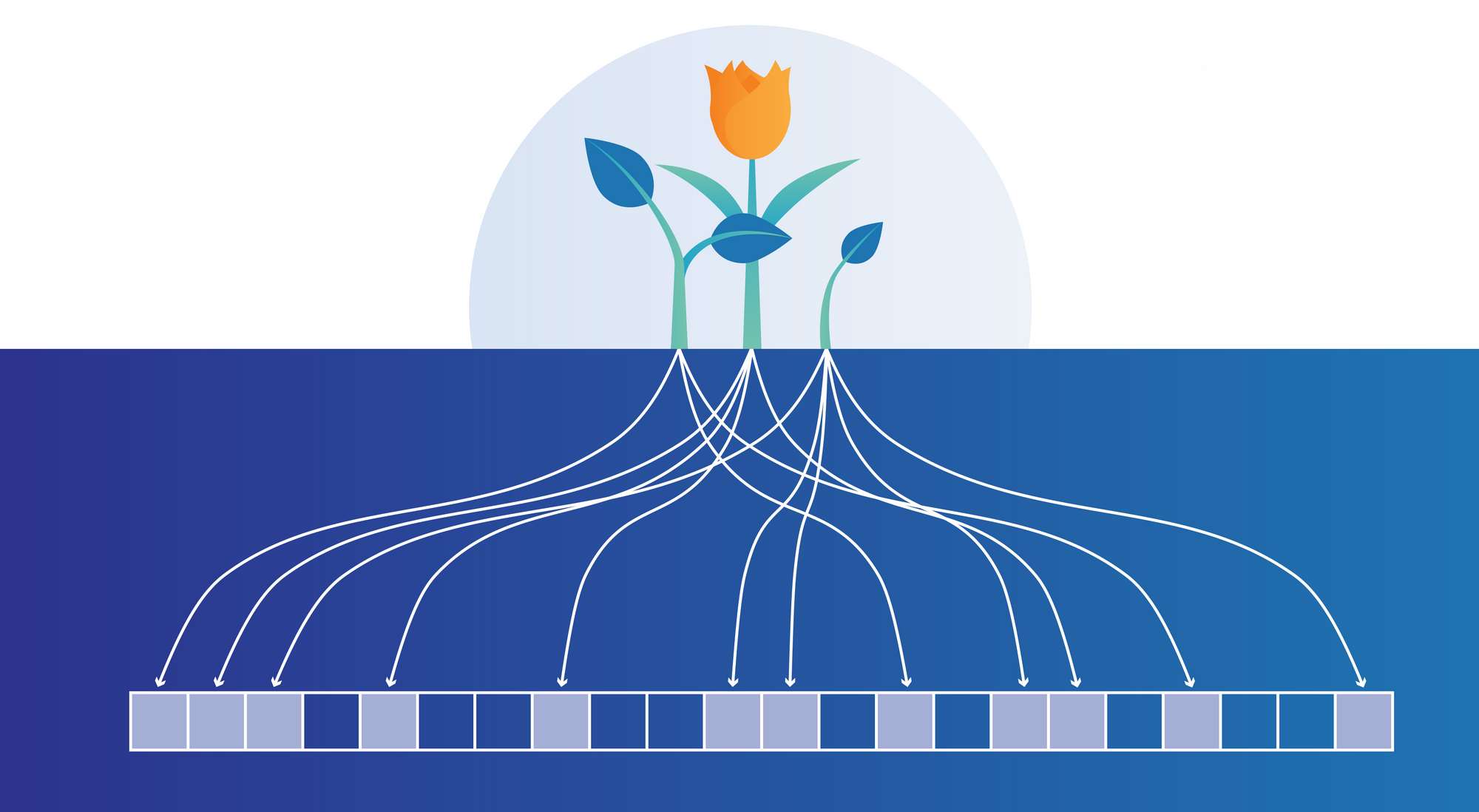
Bloom filter representation is one dimensional array initiated with zeros (length is m).
There are two steps to use the Bloom filter:
- Adding elements to the Bloom filter.
- Checking if an element exists in the Bloom filter.
When we add elements to the Bloom Filter we use hash functions to seed the initial array. The element that we want to add to Bloom filter we can use more than one hash function (number of hash functions is k). Hashed input will mark ones in this initiated array.
The Bloom filter essentially consists of a bit-vector or bit-array (a list containing only either 0 or 1-bit value of length m). Initially all values are set to zero, as shown below.

To add an item to the bloom filter, we feed it to k different hash functions and set the bits to one at the resulting positions. As we can see, in hash tables we would’ve used a single hash function, and, as a result, had only a single index as output. But in the case of the Bloom filter, we would use multiple hash functions, which would give us multiple indexes.
In the above example:
- m = 10 -> length of the bitarray
- k = 2 -> number of hash functions
Bloom Filter in Python
import mmh3 # 3rd party library
class Bloomfilter:
def __init__(self, size: int, hash_count: int) -> None:
self.size = size # m
self.hash_count = hash_count # k
self.bitarray = [0] * size # We initiate the bitarray with 0 values
def add(self, element: str) -> None:
# To add the element to bitarray we use hash function to find the index
# of the bitarray that will be set to 1
for seed in range(self.hash_count):
index = mmh3.hash(element, seed) % self.size
self.bitarray[index] = 1
def lookup(self, element: str) -> bool:
# For checking the existence in Bloom filter we hash it with same
# hash function in add method and we check if all bitarray are set to 1
# if not that means the element doesn't exist.
for seed in range(self.hash_count):
index = mmh3.hash(element, seed) % self.size
if self.bitarray[index] == 0:
return False
return True
Usage
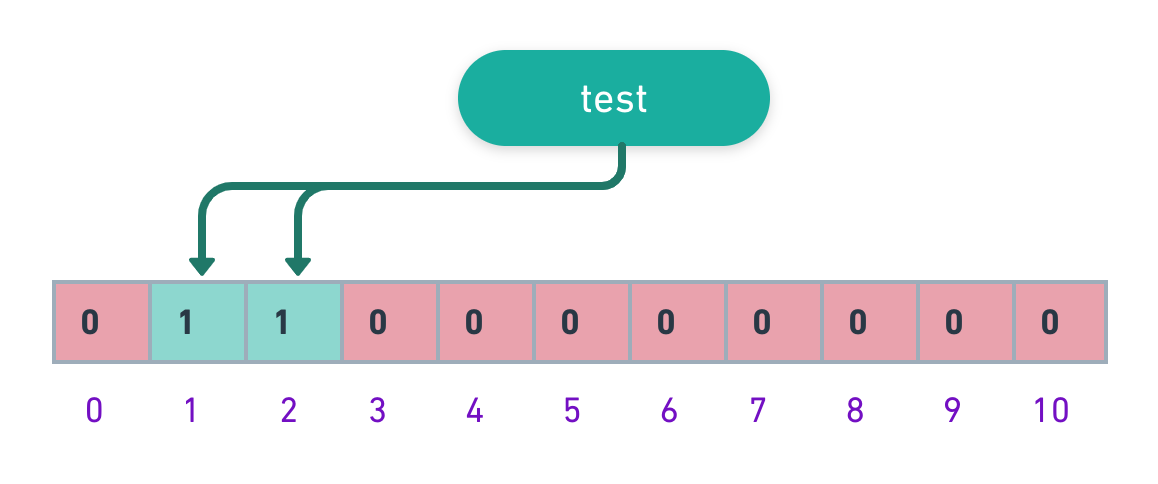
>>> bloom_filter = Bloomfilter(10, 2)
>>> print(bloom_filter.bitarray)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
>>> bloom_filter.add('test')
>>> print(bloom_filter.bitarray)
[0, 1, 1, 0, 0, 0, 0, 0, 0, 0]
>>> assert bloom_filter.lookup('test')
>>> assert not bloom_filter.lookup("does not exist")
>>> |
The classic example is using Bloom filters to reduce expensive disk (or network) lookups for non-existent keys.
If the element is not in the Bloom filter, then we know for sure we don’t need to perform the expensive lookup. On the other hand, if it is in the bloom filter, we perform the lookup, and we can expect it to fail some proportion of the time (the false positive rate).
In our use case the main purpose of using Bloom filter is not to reduce data size or to perform faster data lookups but to make sure that our company is confirming GDPR regulation and not storing PII data in our server. Basically, we replaced our raw IP blacklist with Bloom filters. Since IPs are considered as Personal data (PII) we are no longer storing raw IPs but a representaiton of them in a bitarray.
We were persisting blacklisted IPs in Bloom filter to disk, because files are more convenient support to transfer data between servers. There are other solutions like using redis which has its advantage in front of files; like centralized data storage, but it can have other drawbacks like availability and concurrency, and it has limitations for quick local development.
Conclusion
The Bloom Filter is a powerful tool for reducing data to single bits which makes it possible to store large amounts of information in only a few megabytes. Furthermore, since the bloom filter is basically one binary array, combined with a hash function, the search is in O(1), if hashing is implemented right. That makes it very useful for new IoT devices with small memory amounts, as well as for tiny PC’s like Raspberry PI and alternatives. Bloom filters can also be used for high-load backends, in streaming applications, caching engines and many more…
The usage of Bloom Filters has also some limitations if the filtered data has additional information. for example in our use case, the IP blacklist has originally a score attached to it which tells how much dangerous the IP is; using a score from 0 to 100. So, I came up with a “new” data structured to not lose this information; I called it the Scored Bloom filter. I wanted to keep this post as simple as possible so probably I will write about in another one.